Navigating Machine Unlearning: A Journey Towards Privacy
Written on
Chapter 1: Introduction to Machine Unlearning
In this initial installment of my exploration into machine unlearning, I share my participation in the NeurIPS 2023 Machine Unlearning Kaggle competition. This marks my first foray into the subject, and I invite you to join me in uncovering new insights!
Get ready for a mix of observations, some sidesteps, and interesting points along the way. Feel free to skip over sections that don't resonate with you, and do share any topics you think warrant further exploration in future posts. Thank you for joining me on this journey!
What's at Stake?
Deep learning has become ubiquitous, enabling the generation of realistic images and the creation of advanced chat systems. However, as our reliance on AI technologies grows, we must tread carefully. It is essential to ensure these systems are secure, address issues like bias, and uphold user privacy.
Throughout this series, I will discuss how to remove specific data from machine learning models without compromising their accuracy. This process goes beyond merely deleting data from a database; it also involves eliminating the influence of that data on the model itself. Recent findings indicate that it may be feasible to ascertain whether an individual's data contributed to the training of a model, raising critical privacy issues.
Chapter 2: Theoretical Foundations
In this section, I will summarize two pivotal studies related to machine unlearning. While I won’t dive deeply into the intricate details, I aim to provide a snapshot of current research in this area. If theoretical discussions aren’t your preference, feel free to move directly to the section about the competition.
In the description of the Kaggle competition, two significant papers are referenced. Let’s start with the first one.
Paper: Understanding Membership Inference Attacks in ML Models
This research quantitatively explores how machine learning models divulge information regarding the individual data utilized for training. The study focuses on membership inference attacks, which seek to determine whether a specific data record was part of the model's training dataset.
Membership inference is executed by constructing a separate machine learning model designed to identify variances in the target model's predictions based on whether the data was included in the training set. The authors developed a new machine learning model to assess if another model exhibited different behavior when predicting data it had or had not encountered during training.
Notably, this study exclusively examines models with black-box access, which allows querying the model for outputs based on inputs, without any knowledge of the internal workings or parameters of the model.
Shadow Training Technique 1. Develop multiple “shadow models” that replicate the target model's behavior, using known training datasets to establish ground truth about membership. 2. Train an attack model on the labeled inputs and outputs from these shadow models.
For detailed methodologies on creating training datasets for shadow training, refer to the original paper.
Chapter 3: Privacy Concerns in Machine Learning
This section provides a deeper understanding of privacy implications within machine learning. If you’re already well-versed in this area, you may skip ahead.
What constitutes a privacy breach in machine learning? The concept known as "Dalenius desideratum" suggests that using a model on data should not reveal more information than was previously known. However, models that adhere strictly to this principle may not be functional.
Another privacy challenge arises when model results can infer sensitive information not meant to be disclosed. For instance, if a model uncovers strong correlations between observable traits and genetic risks, it could inadvertently expose genetic details about individuals.
Privacy breaches can affect not only those whose data was used to build the model but also others from the same demographic, even if their data was not included in the training. This presents a complex challenge since effective models must generalize across populations.
Inference Attacks and Privacy The focus of the referenced paper is on safeguarding the privacy of individuals whose data was included in the training set. A fundamental form of attack is the membership inference attack, where an adversary can ascertain if a specific data record was utilized in training a model.
The attacker operates under the assumption of having black-box access to the model, with success defined by accurately identifying if the record was part of the training set.
Metrics for Attack Accuracy - Precision: Proportion of records identified as members that are indeed members of the training dataset. - Recall: Proportion of actual members from the training dataset correctly identified by the attacker.
The constructed attack model comprises a series of models, each corresponding to a potential output class of the target model, since the target model yields diverse probability distributions based on the true class of the input.
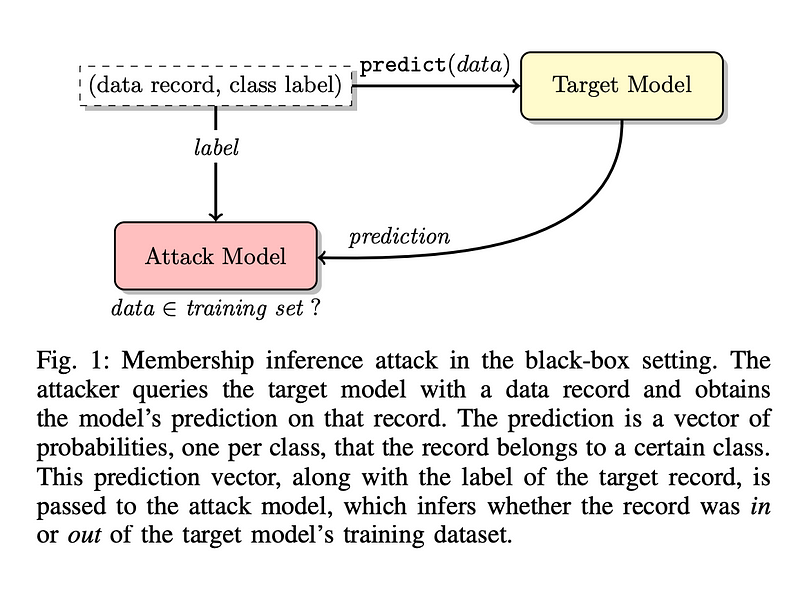
Shadow Models The attacker generates multiple shadow models trained on datasets similar to those of the target model. These shadow training datasets should not overlap with the private training data of the target model. The closer the shadow models resemble the target model, the more effective the attack becomes.
Chapter 4: Conclusion and Competition Overview
In summary, the authors of the first paper developed an attack methodology to determine if particular data points were included in the training of machine learning models, particularly those hosted on cloud platforms like Google Prediction API and Amazon ML. This highlights the unintentional exposure of training data by these models.
NeurIPS ’23 Competition Now, let’s discuss the competition itself. The NeurIPS ’23 challenge revolves around an age predictor model trained on facial images that must “forget” specific training images to protect individual privacy.
Given the capability to ascertain if a data point was used in training, it is crucial to create machine unlearning pipelines that effectively remove the influence of selected training data (the forget set) from a trained model. The ideal unlearning process should preserve the model's accuracy and generalization capabilities.
Participants are tasked with submitting code that processes a trained predictor, along with the forget and retain sets, to output a model that has forgotten the specified data. Evaluations will consider both the effectiveness of the forgetting mechanism and the model's utility. Notably, there is a time constraint to ensure that unlearning is completed within a fraction of the time required for retraining.
The competition provides a starter kit with example algorithms, which I will explore in the next post. Submitted solutions will be assessed based on a metric that evaluates both the quality of the unlearning process and the model's performance.
Stay Tuned! In future posts, I will delve into the provided code examples from the competition. I would love to hear your thoughts on this “Learn to Unlearn with Me” series, any suggested resources, and feel free to connect with me on LinkedIn and X.
Video Description: In this TEDx talk, Navi Radjou discusses the power of unlearning and how it can lead to innovation and growth.
Video Description: This discussion focuses on the importance of unlearning and relearning in expanding our possibilities and perspectives.