Understanding Database Replication: Essential Insights for Developers
Written on
Chapter 1: The Importance of Database Replication
Databases play a vital role in nearly every software application. They serve as structured repositories for data. As companies grow, they inevitably accumulate vast amounts of information, making it critical to protect this data from loss.
While regular backups are a sound strategy (and not just for databases), the backup process can be time-consuming and isn't performed continuously. Consequently, there remains a risk of losing user data collected since the last backup.
This is where database replication becomes essential.
The concept behind replication mirrors that of backups: it involves creating copies of data. However, the key difference lies in the execution. Replication occurs with each modification made to the data, making it an ongoing process rather than a one-time event.
A replicated database provides a comprehensive working copy of the original. This model is particularly beneficial in distributed systems, where components are spread across various locations. Each component can house a database replica, which offers several significant advantages:
- Global Distribution: Replicas can be located near end-users, resulting in lower latency and improved customer satisfaction.
- Faster Read Queries: Since read operations typically outnumber write operations, the system can handle queries more efficiently by distributing the load.
- Increased Resilience: In distributed systems, if one component fails, requests can be rerouted to another machine with an operational database. This ensures continued access to data, even in the event of an internal error.
Section 1.1: The Mechanics of Implementation
Although the concept is straightforward, actual implementation presents challenges. Each database in a distributed system cannot share identical roles. Some databases are designated solely for write requests, while others are reserved for read requests. The database that handles write operations is termed the Leader, while the read-only database is known as a Follower.
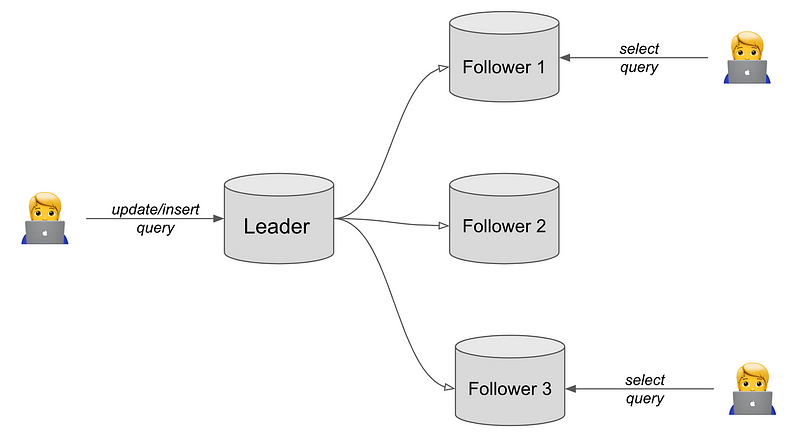
In the illustration above, there is one Leader replica and three Followers. Given the higher frequency of read queries, the system typically has more Followers than Leaders.
When a user updates data, their request is processed by the Leader. After successfully modifying the information, the Leader then updates the Followers, ensuring they all reflect the latest data.
Replication can be classified as either synchronous or asynchronous.
- Synchronous Replication: The Leader waits for confirmation from each Follower before proceeding. While this guarantees robust data consistency, it can lead to longer processing times.
- Asynchronous Replication: In this model, the Leader doesn’t wait for responses from Followers, which can result in temporary inconsistencies across different Followers. This trade-off, known as eventual consistency, is often accepted to enhance write query speeds.
What occurs if the Leader fails? Does this halt the entire system? In such cases, one of the Followers can be promoted to Leader, enabling it to accept write requests.
Chapter 2: Exploring Multi-Leader Implementations
While promoting a Follower to Leader mitigates some risks, it can still create vulnerabilities and slow down processes. This leads to the consideration of a multi-Leader replication scenario.
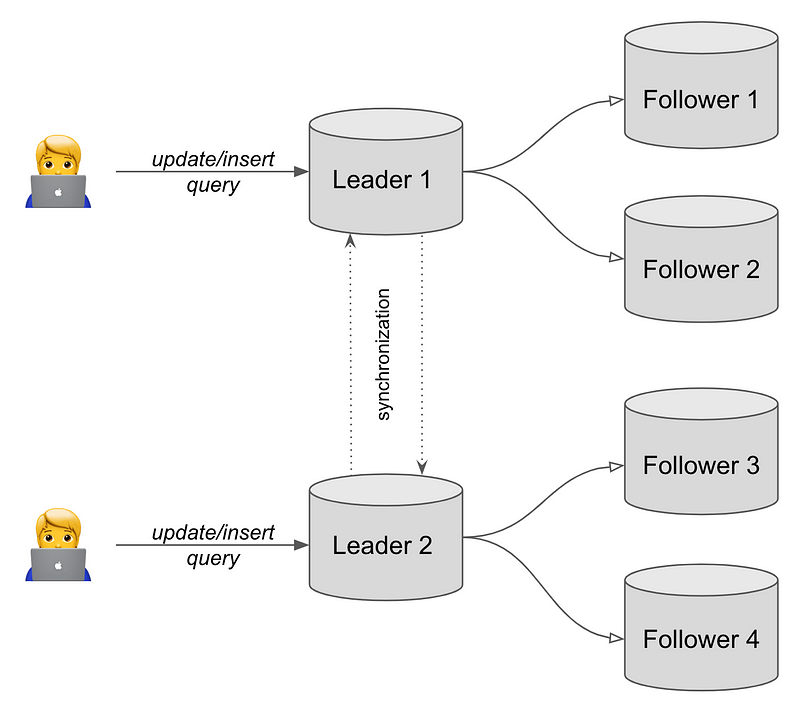
In a multi-Leader setup, additional synchronization among Leaders is necessary. When a user updates data through one Leader, the other Leaders must be informed of these changes.
Conflicts are inevitable when two Leaders attempt to modify the same data. Various conflict resolution strategies exist, such as allowing one Leader to overwrite another's changes or requiring users to manually reconcile differences. This complexity can challenge system management.
However, a multi-Leader replication architecture offers distinct advantages, particularly in fault tolerance. If one Leader fails, requests can be redirected to another, maintaining system stability and performance.
For collaborative applications like Google Docs, where simultaneous editing by multiple users is required, a multi-Leader system is especially beneficial. Users from diverse locations can edit the same document at once, taking responsibility for resolving any conflicts that arise.
Final Thoughts on Data Replication
In today's digital landscape, where traffic is continuously increasing, data replication is no longer optional but a necessity. It not only mitigates disaster risks and data loss but also enhances overall system performance.
Ultimately, the value of database replication is underscored by its critical role in modern software solutions.
Understanding how database replication works is crucial for system design. This video provides insights into its significance.
A concise explanation of database replication in just five minutes. Learn the fundamentals and importance in this brief overview.