Unlocking the Secrets of Transformers: Insights from Dictionary Learning
Written on
Chapter 1: Introduction to Transformers
Transformers have emerged as foundational elements for cutting-edge natural language processing (NLP) models. Despite their formidable capabilities, the intricacies of their operation remain somewhat elusive. This opacity raises concerns about the potential for biases to be embedded in models, which may result in unjust or inaccurate predictions.
In the research paper titled Transformer Visualization via Dictionary Learning: Contextualized Embedding as a Linear Superposition of Transformer Factors, a collaborative team led by Yann LeCun from Facebook AI Research, along with scholars from UC Berkeley and New York University, employs dictionary learning techniques to shed light on transformer representations. They aim to unveil the semantic frameworks that transformers capture, including word-level disambiguation, sentence structure patterns, and long-range dependencies.
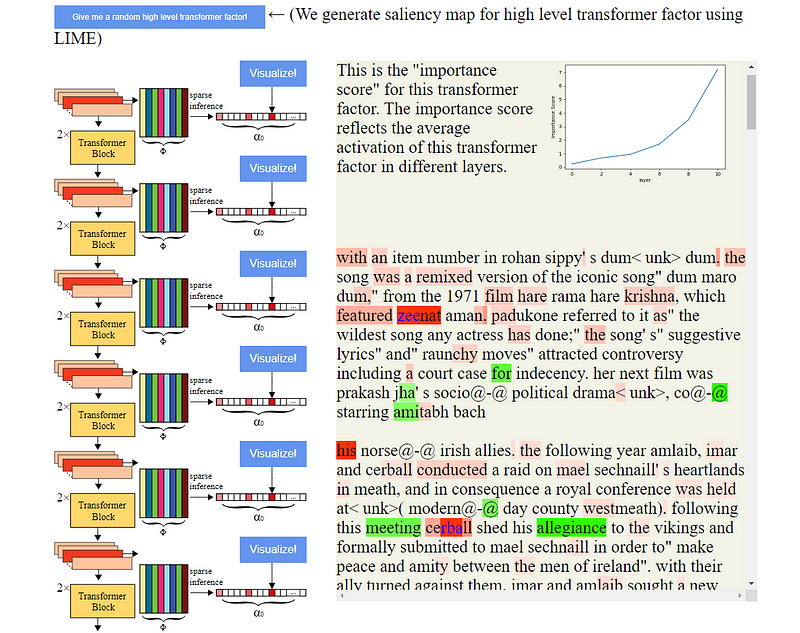
Section 1.1: Challenges in Transformer Interpretability
Prior efforts to demystify the "black box" nature of transformers have included direct visualizations and probing tasks, such as parts-of-speech (POS) tagging, named-entity recognition (NER), and syntactic dependency analysis. However, these techniques often fall short in complexity and do not convincingly capture the true capabilities of the models. Moreover, they struggle to illustrate the deeper semantic structures within transformers and identify where specific representations are acquired.
The researchers advocate for the adoption of dictionary learning, a method that enhances, clarifies, and visualizes uncontextualized word embeddings, as a solution to the shortcomings of current transformer interpretation methods.
Subsection 1.1.1: The Role of Dictionary Learning
The team posits that contextualized word embeddings can be viewed as a sparse linear combination of transformer factors. Earlier studies have established that word embeddings can encapsulate fundamental semantic meanings. They approach the latent representation of words through contextualized word embeddings, suggesting that these vectors can also be decomposed into sparse linear combinations of a defined set of elementary components, referred to as "transformer factors."
They utilize input samples that activate specific features to visualize aspects of deep learning. Because a contextualized word vector is influenced by multiple tokens in a sequence, each token is assigned a weight to indicate its significance relative to the most prominent coefficients of the contextualized word vectors.
Chapter 2: Methodology and Findings
The researchers conducted evaluations using a 12-layer pretrained BERT model. They classified semantic meanings into three categories: word-level disambiguation, sentence-level pattern formation, and long-range dependencies, producing comprehensive visualizations for each category.
The first video features Yann LeCun discussing the complexities of intelligence and the role of self-supervised learning, providing further context to the research.

Section 2.1: Word-Level Disambiguation Insights
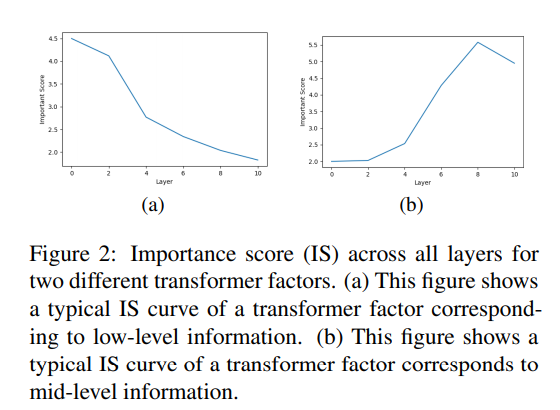
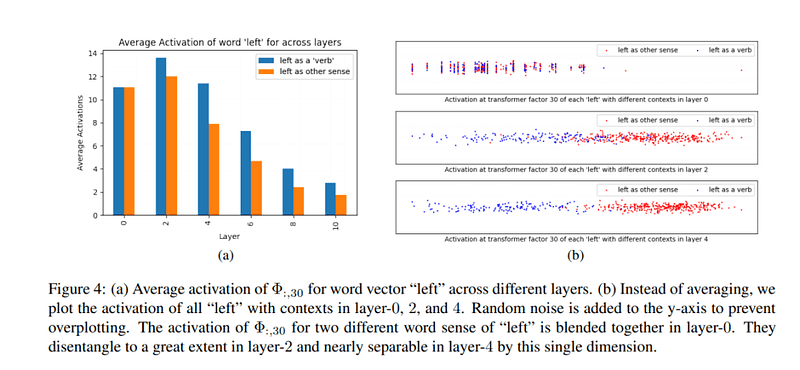
For word-level disambiguation, transformer factors that peaked early in importance scores (IS) typically aligned with specific meanings of words. For instance, in layer 0, the word "left" can convey multiple meanings, but its interpretation becomes more precise by layer 2. By layer 4, all instances of "left" are recognized to signify the same meaning.
The team also quantified the model's ability to disambiguate, enabling the categorization of sentences containing "left" annotated as a verb, distinct from other meanings.

Section 2.2: Sentence-Level Patterns
In terms of sentence-level patterns, the method identified trends in the usage of adjectives. Results indicated that a discernible pattern emerged by layer 4, developed further by layer 6, and became increasingly reliable by layer 8. The majority of transformer factors that peaked in IS after layer 6 captured more complex semantic meanings.
In the second video, Yann LeCun discusses the future of objective-driven AI, emphasizing the importance of systems that can learn, remember, reason, and plan.
Section 2.3: Long-Range Dependencies
For long-range dependencies, transformer factors were associated with linguistic structures that extend across lengthy segments of text. The findings illustrated the top two activated words and their surrounding contexts for each transformer factor. The analysis revealed that these high-level components entail more abstract repetitive structures, which can leverage mid-level information such as names and relationships to create comprehensive narratives.
The researchers assert that their straightforward tool could enhance our understanding of transformer networks, revealing the layered semantic representations acquired at different stages. They have also developed an interactive website where users can visualize transformer models and explore their latent spaces.
The research paper Transformer Visualization via Dictionary Learning: Contextualized Embedding as a Linear Superposition of Transformer Factors is available on arXiv.

Stay updated on the latest news and breakthroughs in AI by subscribing to our popular newsletter, Synced Global AI Weekly.